

The required app, Google AI Edge Gallery, is available for free on Android and iOS. After the release of Gemma 4, it climbed to number 4 among the most downloaded free productivity apps in the iOS App Store, just behind Claude, Gemini, and ChatGPT.
Gemma 4 is based on the same research as Google’s proprietary Gemini 3 model, but it is released under the commercially usable Apache 2.0 license. Since the launch of the first generation, the Gemma family has reportedly been downloaded more than 400 million times, according to Google. All models can process text, images, and audio, and support more than 140 languages.
Four variants for different hardware
All models handle text, images, and audio and support more than 140 languages. In the latest version, there are four variants: E2B and E4B are specifically optimized for smartphones. The “E” stands for “effective parameters,” meaning the number of parameters that are actually active during computation. In quantized form, the E2B model takes up about 1.3 GB of storage on the device, while the E4B model uses around 2.5 GB.
The larger 26B and 31B variants are aimed at servers and high-performance computers. The 26B version uses a Mixture-of-Experts architecture with 128 experts, meaning that only 3.8 billion parameters are active at the same time. The dense 31B model offers a context window of up to 256,000 tokens.
Google also optimized the smartphone variants in collaboration with Arm and Qualcomm for current mobile processors. According to Google, Gemma 4 on Android is up to four times faster than the previous generation while using up to 60 percent less battery power. In its own tests, Arm reports an average 5.5x faster input processing speed, provided the device uses a newer Arm processor with the SME2 instruction set, an extension that accelerates matrix calculations for AI models directly on the chip.
What the app can do on a smartphone
The requirements are Android 12 or iOS 17. The two smartphone variants differ in memory needs: the smaller E2B model takes up only about 1.3 GB in quantized form and runs on devices with 6 GB of RAM, while the larger E4B requires around 2.5 GB of model storage and at least 8 GB of RAM.
Two iPhone screenshots of the Google AI Edge Gallery app show, on the left, the skill management screen with activatable skills such as interactive-map, kitchen-adventure, calculate-hash, and text-spinner. On the right, a chat with the Gemma 4 E2B model shows it generating a QR code through an Agent Skill.
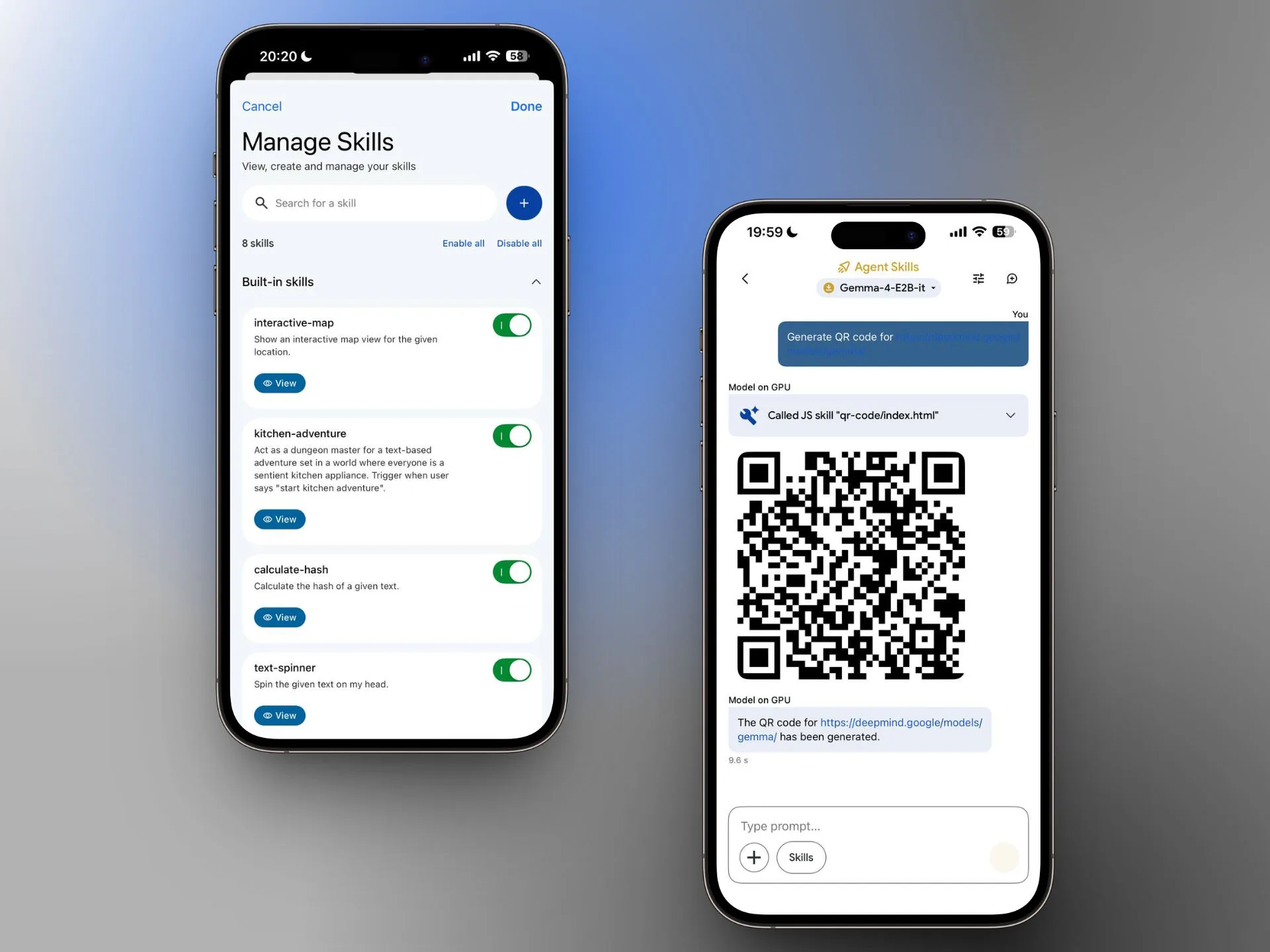
In addition to chat, image recognition, and audio transcription, the app offers so-called Agent Skills: Wikipedia search, interactive maps, automatically generated summaries, and flashcards. Gemma 4 can also describe photos, turn spoken input into charts and visualizations, and even work together with other local models, for example for text-to-speech or image generation. Google demonstrates this with an example skill that describes and plays animal sounds.
According to Google, image recognition also benefits from the new generation: applications involving OCR, meaning the recognition of text in images, charts, or handwriting, now deliver more accurate results. Understanding of time-related expressions has also been improved, which is relevant for calendars, reminders, and alarms.
Two more iPhone screenshots of the Google AI Edge Gallery app show, on the left, a chat with the Gemma 4 E2B model that calls the JS skill “mood-tracker” in response to a text prompt and displays an interactive dashboard. On the right is the full view of the Mood Tracker with a score of 9, a trend chart, and the note “Great time playing pickleball again.”
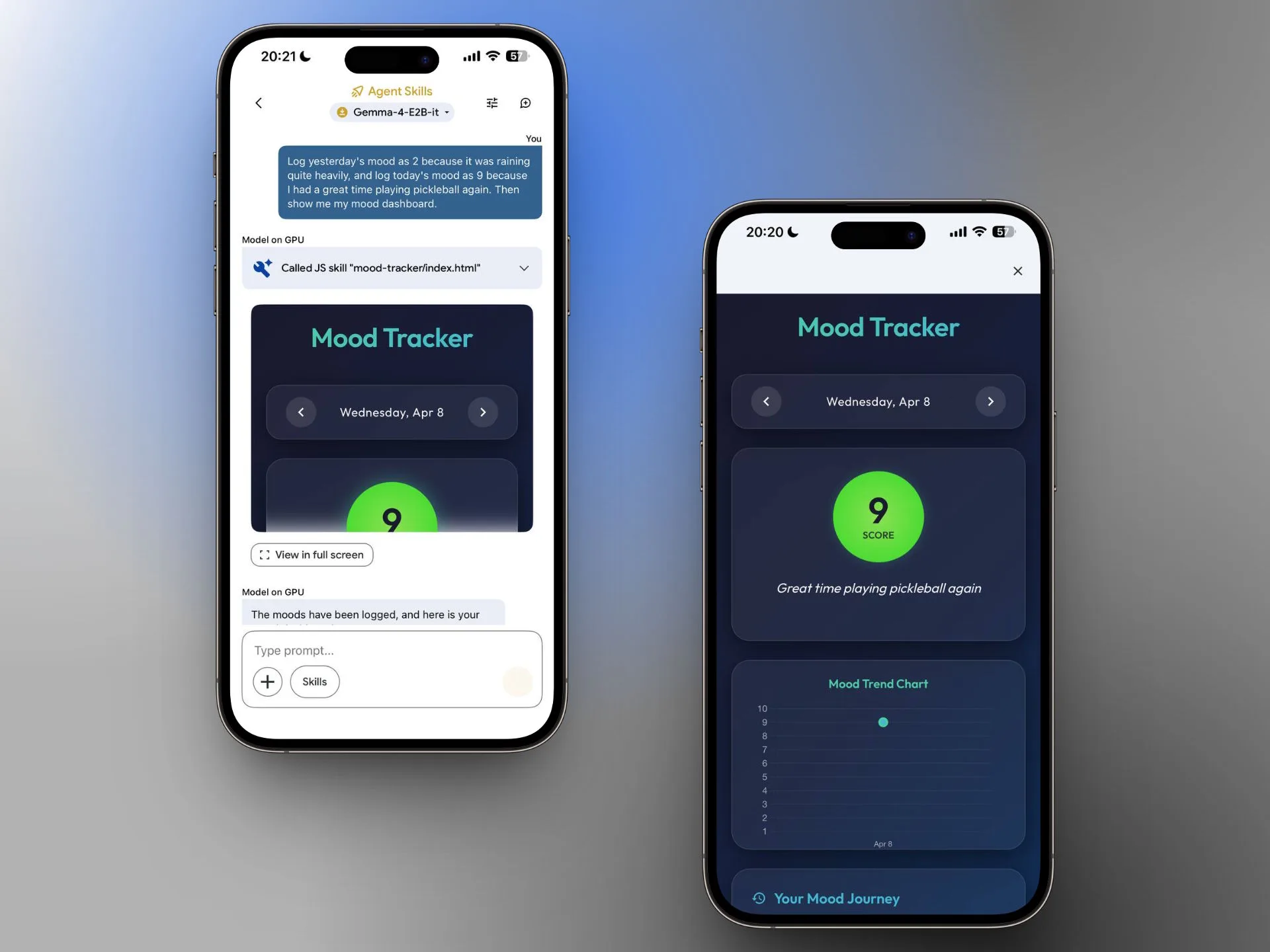
Individually, these features are not particularly remarkable compared with cloud providers. What is noteworthy, however, is that a demo app using a purely local model on a smartphone can now use these tools independently. Developers can also create their own skills via GitHub and share them with the community. While the built-in tools require an internet connection, the model itself continues to run locally. Chats are not stored.
Foundation for the next generation of Gemini Nano
According to Google, Gemma 4 E2B and E4B form the basis for Gemini Nano 4, the next generation of Android’s system-wide on-device model. Code written today for Gemma 4 is expected to be automatically compatible with Gemini Nano 4 when it launches later this year on new flagship devices. Gemini Nano is already running on more than 140 million Android devices, where it is used for features such as Smart Replies and audio summaries.
With FunctionGemma, Google had already shown in December how a small local model with just 270 million parameters can pass commands to other apps on a smartphone. The model translates natural language into structured function calls and can, for example, turn the flashlight on and off, create a new contact, send emails, create calendar entries, display locations on the map, or open Wi-Fi settings.
How strategically important local AI capabilities on smartphones have become is also reflected in the multi-billion-dollar deal between Apple and Google: since January, it has been confirmed that the next generation of Apple’s Foundation Models will be based on Google’s Gemini technology and is expected to power a major Siri upgrade later this year.
Gemma 4 is a major step forward for on-device AI, showing that smartphones can now run multimodal models locally while accessing useful tools through modular skills. Its real significance lies not only in performance, but in how it could accelerate a broader shift from cloud-dependent assistants to private, responsive mobile AI ecosystems.

 ES
ES  EN
EN